Serverless platforms into 2022 — AWS, Cloudflare Workers, Netlify, Vercel, Fly.io
I love #serverless platforms 🚀 I have used most of the public offerings over the years, and I always keep an eye out for new services. In this article I explain the different types of compute, edge vs regional, and make a comparison among the most popular providers. I know there are more providers out there offering serverless products but I included the ones I personally tried. Anything else can be mapped to one of these anyway for comparison.
Disclaimer: All data shown below is as of Jan 20, 2022.
Compute @ Edge vs Regional
There are a few confusing terms floating around, not uncommon for our industry unfortunately, so let’s try to clarify things. One of the most important differences among the different platforms is their answer to the question where does my code run?
Check Amazon CloudFront’s presence map:
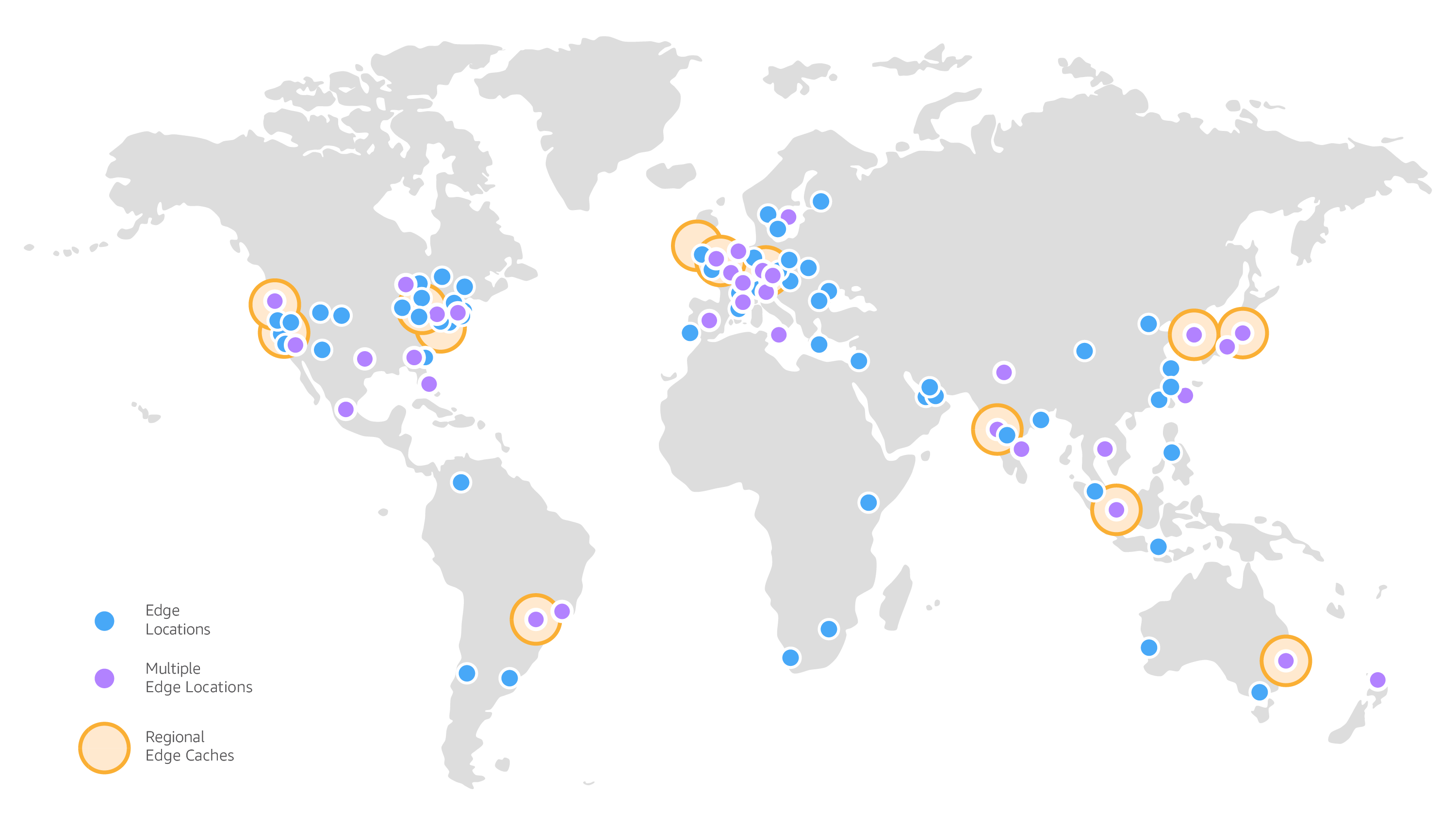
Looking at the legend, and then the map, we can immediately see that the most important distinction between Edge locations and Regions is how many there are of each. We have 300+ Edge locations, or Points of Presence (PoP), and 13 Regional Caches (bigger orange circles). The Regional Caches are mostly backed by standard AWS regions.
For comparison let’s look at Cloudflare’s global map of more than 250 edge locations:
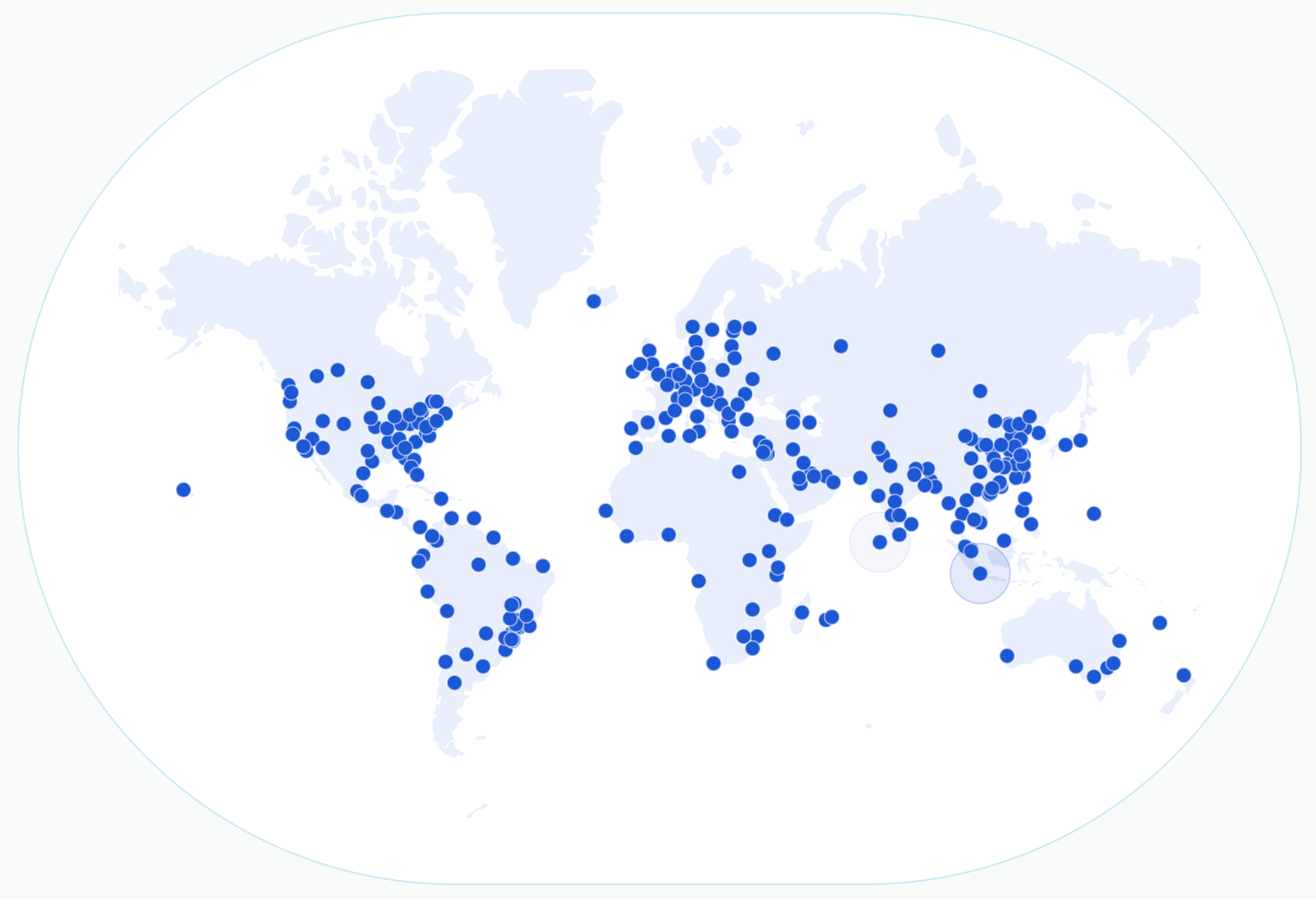
So, what’s the main difference between an edge location, and a regional location? Well, there are a lot more edge locations, and they are more spread around the world. This means that users are more likely to be closer to an edge location rather than a regional location.
- Compute - Edge: When platforms say they offer edge compute, the reasonable assumption is that they run our code in all of these edge locations in their underlying CDN infrastructure.
- Compute - Regional: When we have the traditional regional compute it means that we decide which region will run our code, and then all users have to reach that single region.
- Compute - Multi-regional: We also have the middle ground where our code runs in the regional locations, but we don’t explicitly specify which one. This implies that the provider will run our code in the region that is the closest to the user making the request.
The selling point of running on an edge compute platform is that our customers will get faster response times since our code runs closer to them. However, keep in mind that if the code needs access to a database or calls into external services, it means that those services are now a bottleneck and add to the overall latency. Everything has tradeoffs and the right choice depends on several factors.
Now that the terms are understood, let’s see how the different platforms compare.
The platforms
In this section I will briefly enumerate all the platforms, and what they offer. AWS has multiple serverless products, each with different features, so I will list them separately.
AWS Lambda - Regional
Run code without thinking about servers or clusters
The service that started it all in 2014! Easily the most popular serverless product, and with the most available integrations both inside the AWS ecosystem, but also with other SaaS products. AWS Lambda over the years got many features, and at the moment it supports many runtimes.
- Languages (natively): Go, Node.js, Python, Ruby, Java, C#, PowerShell
- Languages (custom runtime): Any language as long as you implement the custom runtime API (since 2018)
- Containers: Any Docker container implementing the Runtime API, Extensions API, and Logs API (since 2020)
- Memory: 128MB up to 10GB
- Runtime: 29s (HTTP integration with API Gateway), 15min (anything else)
- Uploaded Bundle size: 50MB (zipped), 250MB (unzipped), 10GB (container image)
Looking at the above features, it’s quite clear that AWS Lambda can run pretty much anything now 🚀 But you should be aware of the cold starts…
AWS Lambda@Edge - Multi-regional
Run your code closer to your users
Lambda@Edge launched soon after Cloudflare Workers (see below) came out so many consider this a rushed response to Workers. Its goal is to run our code in the region closest to the user making the request. Therefore, despite its name containing the word edge, it’s not an edge compute product as per our above definition. Yes, this definitely has many people fooled.
Lambda@Edge is a product that can be used only with a CloudFront distribution, and you specify which events to handle while the request flows through the CloudFront cache systems, e.g. before checking the cache, or after the origin returned a response. Read the docs for details about the different integration triggers.
- Languages: Node.js, Python
- Memory: 128MB (Viewer triggers), 10GB (Origin triggers - same as AWS Lambda)
- Runtime: 5s (Viewer triggers), 30s (Origin triggers)
- Uploaded Bundle size: 1MB (Viewer triggers), 50MB (Origin triggers)
I have used Lambda@Edge extensively while working at Amazon/AWS and it’s great. The 1MB bundle size limitation was the only issue we bumped into until we minified our JavaScript.
Amazon CloudFront Functions - Edge
lightweight functions in JavaScript for high-scale, latency-sensitive CDN customizations
CloudFront Functions launched last year in 2021 as one yet another competitor to Cloudflare Workers, but yet again a limited one in my opinion. CloudFront Functions is a proper edge compute product, since our code runs in all of CloudFront’s edge locations. I do use it in my own website (the one you are reading now) and it does the job, but its runtime restrictions limit the potential use-cases, especially since you are not allowed to make any external API calls or even access a filesystem.
- Languages: Custom JavaScript runtime
- Memory: 2MB
- Runtime: 5s (Viewer triggers)
- Uploaded Bundle size: 10KB
It’s clear this is a pretty restricted environment, which to be fair is implicitly acknowledged by AWS judging by the use-cases they list as ideal for the product.
Cloudflare Workers - Edge
Deploy serverless code instantly across the globe to give it exceptional performance, reliability, and scale.
Workers was one of the first true edge compute offerings and pushed the whole industry forward. The main differentiator is that Workers run in V8 isolates eliminating cold starts completely, and allowing near-instantaneous execution very close to users. Note that the V8 environment is not a full Node.js runtime which means it’s not possible to run everything.
- Languages: JavaScript/TypeScript, WebAssembly
- Memory: 128MB
- Runtime: 50ms (Bundled Plan), 30s (Unbundled Plan - HTTP), 15min (Unbundled Plan - Cron trigger)
- Uploaded Bundle size: 1MB
One important feature of Cloudflare Workers is that the runtime is measured in CPU consumption for the Bundled Usage plan, meaning that external API requests (fetch requests) do not count towards the limit. However, for the Unbundled Usage plan the runtime is measured in wall-clock time, so we are charged for the whole duration of the worker running, including external calls.
The biggest advantage of Workers over its competitors is that it’s extremely nicely integrated with the rest of Cloudflare. It natively supports accessing and updating the CDN cache, it provides Durable Objects which are very powerful, and it has a Key-Value store built-in.
Another recent addition is the native integration of Workers with Cloudflare Pages which enable full-stack application development completely on Cloudflare. With Cloudflare R2 Storage around the corner this is going to be a very big threat to AWS Lambda dominance.
Netlify / Vercel - Edge + Regional
Develop. Preview. Ship.
Netlify and Vercel are the most popular serverless products among the frontend community. Their focus is entirely on improving the developer experience for frontend developers, and they are doing an incredibly amazing job. Vercel standardised the phrase Develop. Preview. Ship. and Netlify straight up competes with them at that.
I have been using both of them on-and-off for several years and honestly feature-wise they are identical. From my perspective the differences between them are in their satellite (or secondary) features. Vercel focuses on extending their platform’s features (e.g. Next.js Live), and adding native optimisations for Next.js (their amazing React-based framework) e.g. Image Optimization. Netlify on the other hand provides several features that are complementary to a frontend application, like Identity, Forms, Split Testing and more.
The interesting fact about these platforms is that they are built on-top of the products I went through above.
Their serverless functions products (Netlify, Vercel) are directly build on-top of AWS Lambda, and their edge functions are built on-top of Cloudflare Workers (Netlify, Vercel). Weirdly though, Netlify lists their edge handlers memory limit as 256MB, whereas Cloudflare Workers tops at 128MB, so I am not sure what’s going on there, if there is a special agreement between them, or if they actually run these on their own network!
So, are Netlify and Vercel the best products to use? Should everyone migrate their AWS (or other) serverless apps to them since they combine both? Well… Nope 😅
These products provide top-notch developer experience but it comes at a cost. Their serverless offerings are more limited than their native counterparts:
- Serverless functions:
- Netlify: only
us-east-1region, 1GB of memory, 10s synchronous execution - Vercel: only
IAD1region, 1GB of memory, 5s synchronous execution (15s on Pro, 30s on Enterprise)
- Netlify: only
- Edge functions:
- Netlify: 256MB of memory, 50ms runtime
- Vercel: 1.5s runtime (after returning a response it can still run up to 30s)
Some of the above limits can be lifted for their paid plans, but mostly the Enterprise ones.
Cloudflare Pages gets an honorary mention in this section since it now competes in this space by offering a seamless integration with source code repositories, and serving Jamstack websites, while at the same time having built-in integration with Cloudflare Workers.
The above limitations are why I personally still use AWS Lambda directly when I want an API, and combine it with Cloudflare Pages for the frontend. However, if your application does not need more resources than what these platforms offer, which to be fair most websites don’t, then you are fine just using them and focusing on your application. This is exactly what I did when I built Minibri Temp with Netlify.
Fly.io - Multi-regional
Fly keeps your performance up by sending users on the shortest, fastest path to where your application is running.
Fly.io is a relatively new player (launched in 2020) but it definitely attracted many people already. It currently has 20 regions and the selling pitch is that you specify a Docker image for your application and depending on where the user is they will spin up an instance of it to the closest region and serve the request. Very similar to how Lambda@Edge works, but incredibly more flexible!
- Containers: Docker images, Cloud Buildpacks
- Memory: 256MB-2GB (shared-cpu), 2-64GB (dedicated-cpu)
- Runtime: No limit, pay per second
- Uploaded Bundle size: n/a
This is more like a traditional container product, but I included it because they do offer the multi-regional flavor, and they even have multi-region Postgres databases with a nice architecture. If their scaling is fast enough not to have long cold-starts then this should be a very nice middle-ground between fully edge or fully single-regional.
I haven’t used Fly.io a lot but I do like its approach and based on the feedback from others I definitely plan to give it a go with one of my side projects.
Fun fact: While writing this post, Fly.io announced 3GB Postgres or persisted volumes in the free tier 🥳
Conclusion
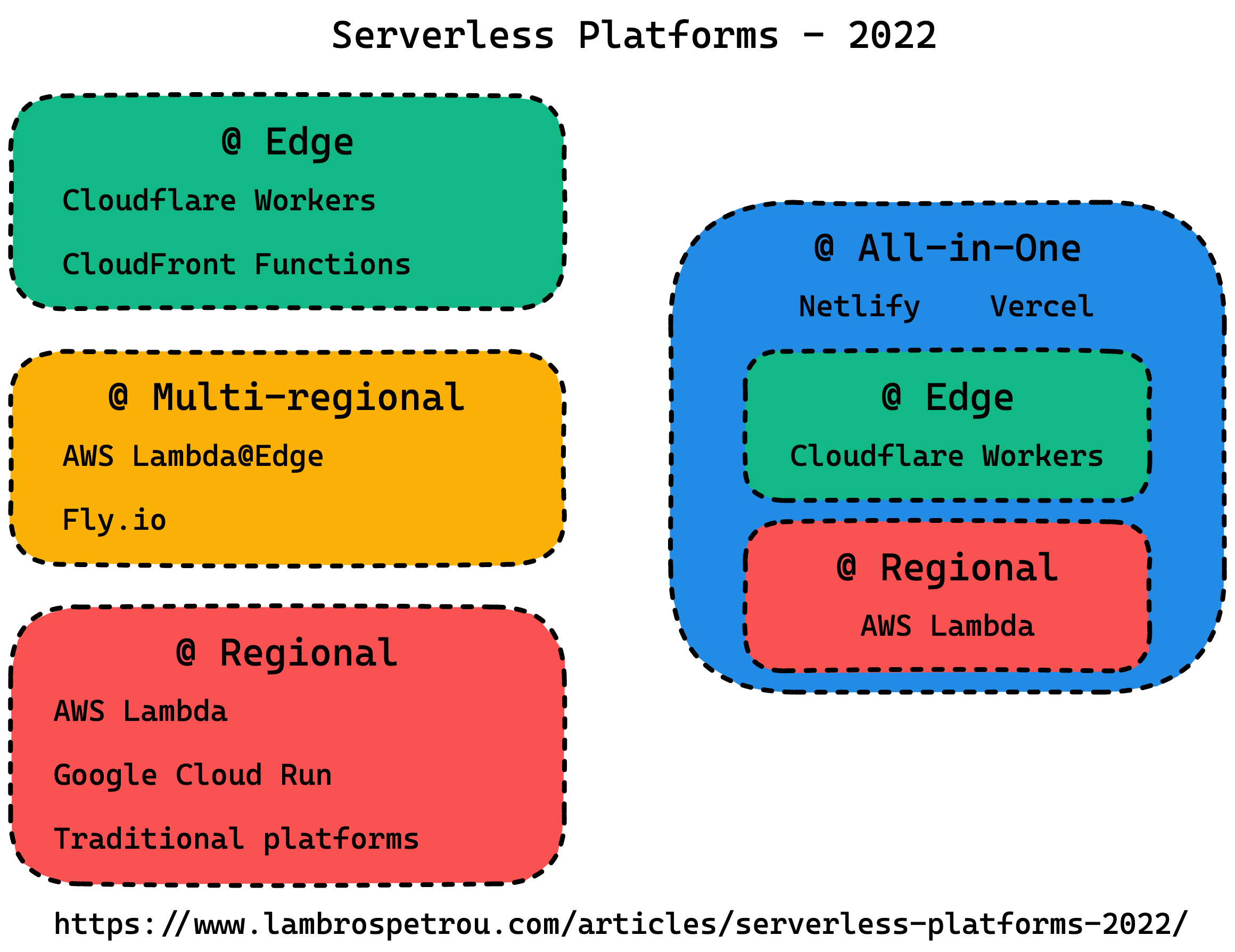
The diagram above summarises the platforms we discussed. Each one has its benefits and drawbacks, but the choice we have nowadays is amazing! I am pretty sure things will continue to evolve, improve, and we will see a lot more innovation in this space.
I have my favourites, you have yours, so let’s just keep on building 😉