Makefiles for execution coordination
As the title implies, this article is about the now ancient tool make [1] [2]. This little gem of software is used in our industry for at least 45 years now.
To be fair, I haven’t personally used it in big projects at work, but I regularly use it for my personal side projects since it gets the job done, and it provides a language agnostic common interface which means I can use it for Javascript projects, Kotlin projects, Golang projects, and others.
Enough with the intro though, in this article I will describe a very simple problem I wanted to solve recently and the good old make turned out to be the best solution, versus all the newer, shinier, and way more bloated modern alternatives.
Problem
The problem at hand is simple, and common to many people. I want a simple workflow tool to run some local programs in a specific order, each one potentially generating some output files to be used as input by subsequent programs in the workflow, and ideally parallel execution for the steps that do not depend on each other. A simple file processing data pipeline, to fully run locally on my laptop.
Simple eh… 🤪 😅
I did spend a few days looking for available tools but I was surprised that most of the modern workflow tooling is extremely bloated, complicated, and most of them made for “web scale distributed systems”, even though most people don’t really need that.
Candidate solutions:
- https://snakemake.github.io
- This is the best available tool I found, and if you notice its name it hints to the
maketool. It has simple declarative way of expressing the workflow steps, their inputs and outputs, and the tool figures out the order in which to execute them. I really liked its documentation but I ended up not using it since it is built ontop of Python, and I don’t like Python…
- This is the best available tool I found, and if you notice its name it hints to the
- Do-it-myself
- The first thought I actually had was to just write a quick script in Go and shell out to the programs I wanted to execute, with as much parallelism and dynamism I needed. For a one-time script this is my goto, but I wanted to find a way to define the workflow declaratively, and learn something that could be used in the future for other more complicated flows as well.
make
I chatted with a friend about this and he instantly said “just use make”. I knew make was the main build tool for C/C++ projects, with fancy dynamic rules, running only the steps that have to run in the right order, and with good performance. I never used it though solely as an orchestration tool, with nothing to compile…
If you are not familiar with make, these are great resources on writing Makefiles:
- https://makefiletutorial.com/
- https://swcarpentry.github.io/make-novice/reference.html
- https://www.gnu.org/software/make/manual/make.html (the actual manual)
Flow 1 - Parallel File Processing
The first example workflow does the following:
- Process all JSON files inside a directory
data/. For each JSON fileFwe want to call some commandCthat will processF. This ideally should be done in parallel since there could be lots of files. - Once all the files are processed, run another command which can continue the workflow execution.
Even though the workflow is simple, it still showcases how to use all the things we need:
- Parallel execution of independent steps
- Ordered execution of dependent steps

The following Makefile (filename flow1.mk) implements the above workflow.
MAKEFILE_NAME = flow1.mk
DATAFILES = $(wildcard data/*.json)
default: boom
# Trigger a recursive `make` for the target `datafiles_all`.
# The critical argument is `--always-make` which will force the run all the time,
# otherwise `make` will not do anything since the data files are not modified!
boom:
$(MAKE) datafiles_all --always-make -f $(MAKEFILE_NAME)
# A trampoline target that depends on all the data files to force their processing.
datafiles_all: $(DATAFILES)
@echo :: 'datafiles_all' finished!
# The target that corresponds to each JSON file in the `data/` directory.
data/%.json:
@echo "processing single file:" $@
@cat $@
If we run the above makefile using make -f flow1.mk we get the following output:
$ make -f flow1.mk
processing single file: data/a.json
{"a": 1}
processing single file: data/b.json
{"b": 2}
processing single file: data/c.json
"c"
:: datafiles_all finished!
Pretty clear output showing that all three files in the data/ directory were processed.
Parallelism
If we run the above makefile with the additional -j 3 arguments, then all three files will be processed in parallel.
This is not clear with the above example, so let’s make it a bit more complicated to showcase this as well.
# Run with `make -f flow1-parallel.mk -j 3` for parallelism 3
# or with `make -f flow1-parallel.mk -j $(nproc)` to use all processors.
# The default is to process each target one after the other.
MAKEFILE_NAME = flow1-parallel.mk
DATAFILES = $(wildcard data/*.json)
default: boom
# Trigger a recursive `make` for the target `datafiles_all`.
# The critical argument is `--always-make` which will force the run all the time,
# otherwise `make` will not do anything since the data files are not modified!
boom:
$(MAKE) datafiles_all --always-make -f $(MAKEFILE_NAME)
# A trampoline target that depends on all the data files to force their processing.
datafiles_all: $(DATAFILES)
@echo :: 'datafiles_all' finished!
# Special override target for this specific file to simulate a long/slow execution.
data/a.json:
@echo "processing slow file:" $@
@sleep 2
@echo still processing $@ ...
@sleep 2
@echo finished processing $@ ...
# The target that corresponds to each JSON file in the `data/` directory.
data/%.json:
@echo "processing single file:" $@
@cat $@
The only difference in this makefile is the newly added explicit target rule for data/a.json.
By explicitly adding that rule, make will execute those commands instead of the generic statements defined by the data/%.json rule.
Let’s see how this runs with the default make invocation:
$ make -f flow1-parallel.mk
processing slow file: data/a.json
still processing data/a.json ...
finished processing data/a.json ...
processing single file: data/b.json
{"b": 2}
processing single file: data/c.json
"c"
:: datafiles_all finished!
As we can see, we need to completely finish the slow processing of data/a.json before proceeding with the rest files.
Now let’s run it with parallelism 2:
$ make -f flow1-parallel.mk -j 2
processing slow file: data/a.json
processing single file: data/b.json
{"b": 2}
processing single file: data/c.json
"c"
still processing data/a.json ...
finished processing data/a.json ...
:: datafiles_all finished!
In this case, we can see that processing for data/a.json started as before, but before we even get to see the still processing data/a.json ... printout, the other two files are already processed, and then finally data/a.json completes.
make is smart enough with parallelism and no matter how many files, or target rules, we have in the Makefile it will respect the parallelism we specify with the -j N argument and execute the target steps accordingly without exceeding the specified parallelism.
Flow 2 - DAG
Another simple flow I want to show is how to make a pipeline of processes where some depend on each other, and some use local files/pipes as their communication mechanism.
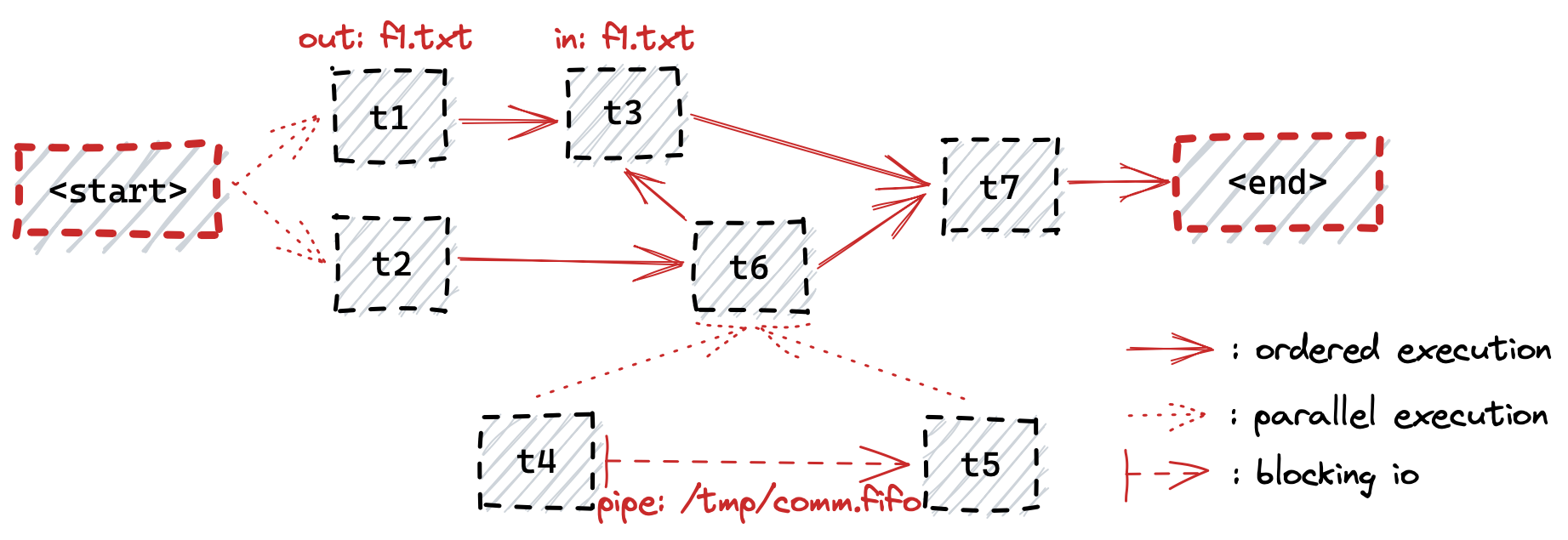
What the diagram above means in plain English?
- Initially we start with the
t1andt2targets executing in parallel. t1writes an output filef1.txtand then proceeds to executet3which will read thef1.txtfile as input (t3depends ont6though, so cannot start untilt6finishes as well).- In parallel to
t1/t3‘s execution flow, oncet2completes it will triggert6, butt6depends ont4andt5targets to have been completed first. t4andt5execute in parallel, and the output oft4is being read byt5through the file pipe/tmp/comm.fifo. Note that this is blocking communication, meaning that in order fort4to manage to finish,t5must also run in parallel to consume the content produced byt4.- Once
t6finishes,t3can execute. - Once both
t6andt3are complete,t7will execute and complete our workflow.
The above workflow is modelled by the following makefile (flow2-dag.mk).
Note how each target defines the dependencies it needs in order to properly coordinate the execution.
.PHONY: t1 t2 t3 t4 t5 t6 t7
default: t7
t1:
@echo "t1"
@echo "t1-content-output" > f1.txt
@echo "t1 output file written!"
t2:
@echo "t2"
t3: t1 t6
@echo "t3"
@cat f1.txt
@echo "t1 output file printed!"
t4_5_setup:
@rm -f /tmp/comm.fifo
@mkfifo /tmp/comm.fifo
t4: t4_5_setup
@echo "t4"
@cat /usr/share/dict/words > /tmp/comm.fifo
t5: t4_5_setup
@echo "t5"
@echo "Total lines: " && wc -l < /tmp/comm.fifo
t6: t2 t4 t5
@echo "t6"
t7: t3 t6
@echo "t7"
Let’s run it and see if it works.
$ make -f flow2-dag.mk -j 4
t1
t4
t2
t5
Total lines:
t1 output file written!
235886
t6
t3
t1-content-output
t1 output file printed!
t7
Boom 🥳 It works as expected 🚀 (exercise to the reader to confirm…)
Note: This workflow requires parallelism of at least 2, otherwise targets t4 and t5 will deadlock. Target t4 will be the only one running, and once it fills up the file pipe it will block until someone consumes it. But since t5 is not running the workflow will be stuck. In scenarios like this, either always make sure to run this with some parallelism, or use normal files as communication, as we did between t1 and t3.
Conclusion
There is no doubt that make is amazingly powerful and flexible enough to achieve any kind of workflow execution. I barely even covered its functionality. I expected it to be much more cumbersome to use due to the complexity I see in how most of the C/C++ projects are using it.
I was pleasantly surprised! For these use-cases when I don’t want complicated bloated tools, make fits the bill perfectly!
The fact that make is available on almost any system, with super fast execution, makes it a great tool in my toolkit.